OCRとは
OCRとはOptical Character Recognition/Readerの略で、オーシーアールと読みます。
光学的文字認識とも呼ばれ、手書きされた文字や印刷された文字など、画像やPDF上の文字を読み取り、文字コードに変換する技術です。
python3でOCRを活用したい場面
OCRを活用するのにはいろいろな用途があると思います。
画像上の文字/数字をOCRで認識する
画像上の文字や数字を認識したいケースに活用できます。
今回は、この点に関してサンプルを作成したいと思います。
WEB上の画像だってOCRで文字認識できる
PyOCRとtesseractのインストール手順
今回はPyOCRを使って実現します。
インストール手順はたったこれだけ。簡単に使える様になります。
Windowsの場合
python -m pip install pyocrLinuxやmacOSの場合
pip install pyocrtesseract-OCRをインストールする
下記リンク先からexeファイルをダウンロードしてください。

exeファイルがダウンロード出来たら、exeファイルを実行し、インストールを進めてください。
手順通りすすめると、以下の様にチェックが外れてる箇所が表示されます。
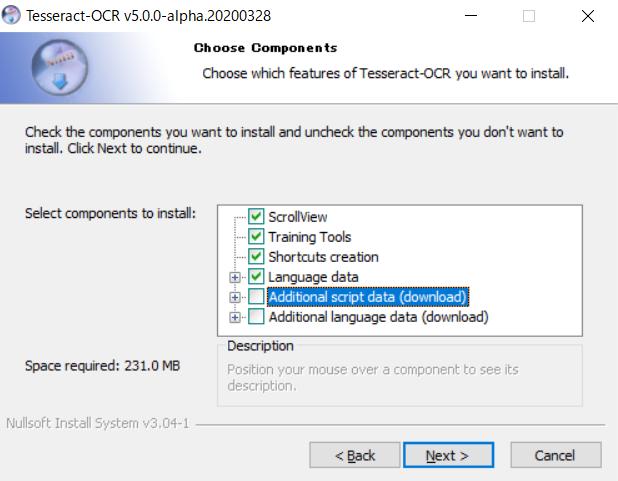
ここでAdditional script data(download)内にあるJapaneseにチェックを入れます。
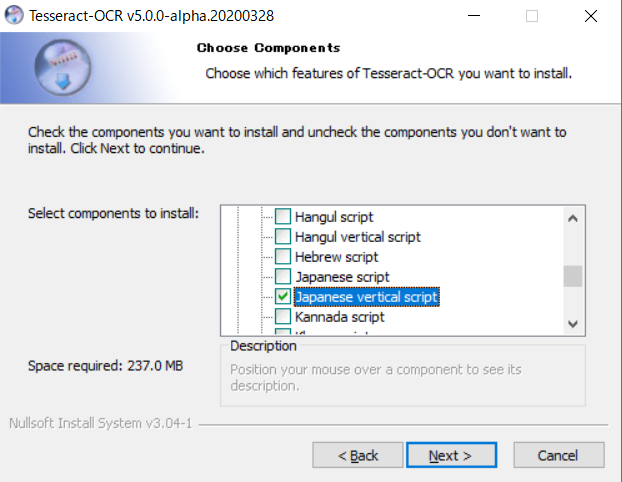
また、Additional language data(download)内にあるJapaneseにもチェックを入れてください。
tesseract-OCRのパス(path)を通す
インストールされた先を一応確認します。
64bit版でfor all userの場合は、例えば次にインストールされます。
C:\Program Files\Tesseract-OCR
次に、PC画面左下のウインドウアイコンを右クリックして検索>「環境変数」>システム環境変数の設定>環境変数>システム環境変数のPathを選択した状態で「編集」>空白行に、上記tesseract-OCRがインストールされたパスを入力して再起動します。
PyOCRを用いて画像認識するサンプルコード
引数として画像のパスを受け取ります。
文字として変換したものをテキストとして返します。
from PIL import Image
import sys
import pyocr
import pyocr.builders
# pngファイルの自動読み取り
def png_to_text(png_name):
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
# The tools are returned in the recommended order of usage
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
# Ex: Will use tool 'libtesseract'
langs = tool.get_available_languages()
print("Available languages: %s" % ", ".join(langs))
lang = langs[0]
print("Will use lang '%s'" % (lang))
# Ex: Will use lang 'fra'
# Note that languages are NOT sorted in any way. Please refer
# to the system locale settings for the default language
# to use.
txt = tool.image_to_string(
Image.open(png_name),
lang=lang,
builder=pyocr.builders.TextBuilder()
)
# txt is a Python string
return txt
# img.pngの内容をテキスト化
keyword_text = png_to_text('img.png')WEB上の画像を文字起こししたい場合のサンプルコード
Chrome Driverとの組み合わせで実装する
Chrome Driverはpythonでクローリングする際に使うと開発が格段に楽になります。
-

pyhon3でWEBクローリングするならSelenium WebDriverを活用しよう(導入手順と使い方)
スクレイピングは情報を「抽出」すること スクレイピングとは「何らかのデータ構造から抽出すること」を指します。 簡単に言う ...
続きを見る

画像上の文字と同一の文字をフォームに入力する必要があるログイン画面の自動ログインサンプルコード
from time import sleep
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from PIL import Image
import sys
import pyocr
import pyocr.builders
# pngファイルの自動読み取り
def png_to_text(png_name):
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
# The tools are returned in the recommended order of usage
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
# Ex: Will use tool 'libtesseract'
langs = tool.get_available_languages()
print("Available languages: %s" % ", ".join(langs))
lang = langs[0]
print("Will use lang '%s'" % (lang))
# Ex: Will use lang 'fra'
# Note that languages are NOT sorted in any way. Please refer
# to the system locale settings for the default language
# to use.
txt = tool.image_to_string(
Image.open(png_name),
lang=lang,
builder=pyocr.builders.TextBuilder()
)
# txt is a Python string
return txt
USER = 'IDをここに記入'
PASS = 'PASSをここに記入'
# seleniumの準備
options = webdriver.ChromeOptions()
# 必須
options.add_argument('--disable-gpu')
options.add_argument('--disable-infobars')
# エラーの許容
options.add_argument('--ignore-certificate-errors')
options.add_argument('--allow-running-insecure-content')
options.add_argument('--disable-web-security')
# headlessでは不要そうな機能
options.add_argument('--disable-desktop-notifications')
options.add_argument("--disable-extensions")
# UA
options.add_argument('--user-agent=hogehoge')
# 言語
options.add_argument('--lang=ja-JP,ja;q=0.9,en-US;q=0.8,en;q=0.7')
# ブラウザーを起動
driver = webdriver.Chrome(chrome_options=options)
# HPにアクセス
driver.get('ログインページURLをここに記入')
# ちょっとだけ待機
sleep(2)
# ID/PASSを入力
id = driver.find_element_by_xpath("実際のidを入れるフォームのxpathを入力してください")
id.send_keys(USER)
sleep(1)
password = driver.find_element_by_xpath("実際のpasswordを入れるフォームのxpathを入力してください")
password.send_keys(PASS)
sleep(1)
# キーワード部分を画像化
png = driver.find_element_by_xpath("OCRにかけたい画像のxpathを入力してください").screenshot_as_png
with open('./img.png', 'wb') as f:
f.write(png)
# 画像を文字列に変換してフォームに入力
keyword_text = png_to_text('img.png')
keyword = driver.find_element_by_xpath("実際のkeywordを入れるフォームのxpathを入力してください")
keyword.send_keys(keyword_text)
# ログインボタンを押す
login_button = driver.find_element_by_xpath("ログインボタンのxpathを入力してください")
login_button.click()



